How to build a LinkedIn scraper in 2026
Build a LinkedIn scraper with AI automation while covering legal and ethical steps.

Building a LinkedIn scraper is about architecting a flow of intelligence. It’s the craft of transforming the vast, chaotic network of public professional data into a structured asset that fuels growth, research, and recruitment. It's not just a tool; it's a data engine.
A LinkedIn scraper automates the extraction of public data from profiles, company pages, and job listings for analysis. A 2024 analysis from PromptCloud shows the web scraping market is set to nearly double to USD 2 billion by 2030, highlighting the intense demand for this data. This guide will show you real CodeWords workflows — not just theory.
- The web scraping market is projected to grow from USD 1.03 billion in 2024 to USD 2 billion by 2030 (PromptCloud, 2024).
- Unlike generic AI automation posts, this guide shows real CodeWords workflows — not just theoretical advice.
- Learn to build resilient scrapers that adapt to website changes, not brittle scripts that break constantly.
Manual prospecting is a dead end. Teams spend countless hours copying and pasting profile details, a slow and error-prone process that fundamentally cannot scale. This tedious work caps outreach and research, leaving a trove of opportunities untouched. You know the intelligence is there, but accessing it feels like an insurmountable chore.
What if you could architect a new system entirely? Imagine replacing that manual chaos with an automated engine that pipes qualified leads and market insights directly into your workflow. By automating data extraction, you can reduce sourcing time by over 70%. This transformation frees your team to build relationships and close deals — not drown in data entry.
But there’s a problem most tools ignore. The common belief is that a reliable scraper requires wrestling with complex Python scripts that break every time LinkedIn updates its interface. That’s the old way. The real solution lies in building resilient systems with modern AI workflow automation, designing a data pipeline that adapts and grows with your business.
Why is automated LinkedIn scraping essential for growth?
The core reason to automate LinkedIn scraping is to overcome the limitations of manual effort. Your team's time is a finite resource, and spending it on repetitive data collection is a direct inhibitor to growth. Every hour spent copying profile details is an hour not spent on strategy, sales, or product development. Automating this process dismantles that bottleneck. It creates a scalable system for intelligence gathering that operates continuously in the background, feeding your other business systems with fresh, relevant data. This is not about saving a few hours; it's about building a foundational data asset.
Here's the deal: this capability is no longer a luxury. The global web scraping market is projected to jump from USD 1.03 billion in 2024 to USD 2 billion by 2030 — a compound annual growth rate of about 14% (PromptCloud, 2024). In Singapore, 63% of operations teams report that manual data entry is a significant barrier to scaling their outreach efforts. This trend signals a critical shift. Companies that architect automated data pipelines are the ones that gain a competitive edge. It's the difference between reacting to the market and actively shaping your position within it. A well-designed LinkedIn scraper is a cornerstone of this modern business intelligence engine, fueling everything from LinkedIn lead generation strategies to competitive analysis.
How do different LinkedIn scraping methods compare?
Choosing a LinkedIn scraping method is a strategic decision, not just a technical one. Your objective is to build an intelligence-gathering system that aligns with your budget, risk tolerance, and the specific data you need. It’s about matching the right tool to the job at hand.
Most people believe you must dive into complex code to get any value. The opposite is often true. Starting with the simplest viable method allows you to prove the concept and see results quickly, before committing to a more intricate setup. The challenge isn't the act of scraping; it's architecting the right approach.
Let's look at the primary methods.
- The official LinkedIn API: This is the sanctioned, completely safe way to access LinkedIn data. It’s designed for integrations, providing clean, structured data. However, LinkedIn controls what you can see and how much you can get. It’s excellent for simple integrations but too limited for serious lead generation or market research due to strict rate limits and data constraints.
- Manual data exports: You can export a list of your own connections directly from LinkedIn’s settings. This method is simple and carries zero risk because it's a built-in feature. The catch? You only get basic information on your 1st-degree connections, making it useful for a personal backup but not a scalable business intelligence tool.
- Browser automation tools: These tools mimic a human user clicking and scrolling in a web browser. They are powerful because they act like a person, making their activity harder to detect. They can handle logins and navigate dynamic pages. The main downside is that they can be slow and resource-intensive. To learn more, check out our guide on the best tools for scraping LinkedIn.
- Headless browser scraping: This is the next level. A headless browser is a web browser without a visual interface, controlled by code. This approach offers the power of a real browser — executing JavaScript and handling complex interactions — without the performance overhead. It’s faster, more scalable, and ideal for large-scale data extraction. However, it is technically demanding and carries the highest risk, requiring advanced tactics like proxy rotation to avoid detection.
What are the legal and ethical rules for scraping LinkedIn?
Understanding the rules for scraping LinkedIn isn't about avoiding trouble; it's about building a data asset that can last. The legal and ethical framework is the foundation of your system. Ignoring it risks having your entire operation shut down overnight. The central legal question was addressed in the landmark hiQ Labs v. LinkedIn case, where the court ruled that scraping publicly accessible data does not violate the Computer Fraud and Abuse Act (CFAA). This was a critical clarification.
But that’s not the full story. While the hiQ ruling protects you from federal prosecution for scraping public profiles, it doesn't stop LinkedIn from enforcing its Terms of Service, which strictly forbid automated data collection. The consequence here isn't a lawsuit — it's a permanent account ban. Furthermore, data privacy laws like GDPR and CCPA govern the collection of Personally Identifiable Information (PII).
The line is clear: only ever touch publicly accessible information.
A responsible framework comes down to a few key practices. First, respect robots.txt, a file that tells bots what not to access. Second, use rate limiting; build in delays to mimic human browsing behavior. A real person can't view 500 profiles a minute, and your scraper shouldn't either. Third, identify your bot with a clear User-Agent string. Finally, take only what you need. Scraping specific fields reduces your security burden under laws like GDPR. As data needs evolve in 2025 towards fresher data and wider geographic scale, the tension between data utility and compliance is only getting stronger, as detailed in this analysis of web scraping trends. These principles aren't limitations; they are smart engineering practices that create a more resilient data engine.
How do you build an automated scraper with CodeWords?
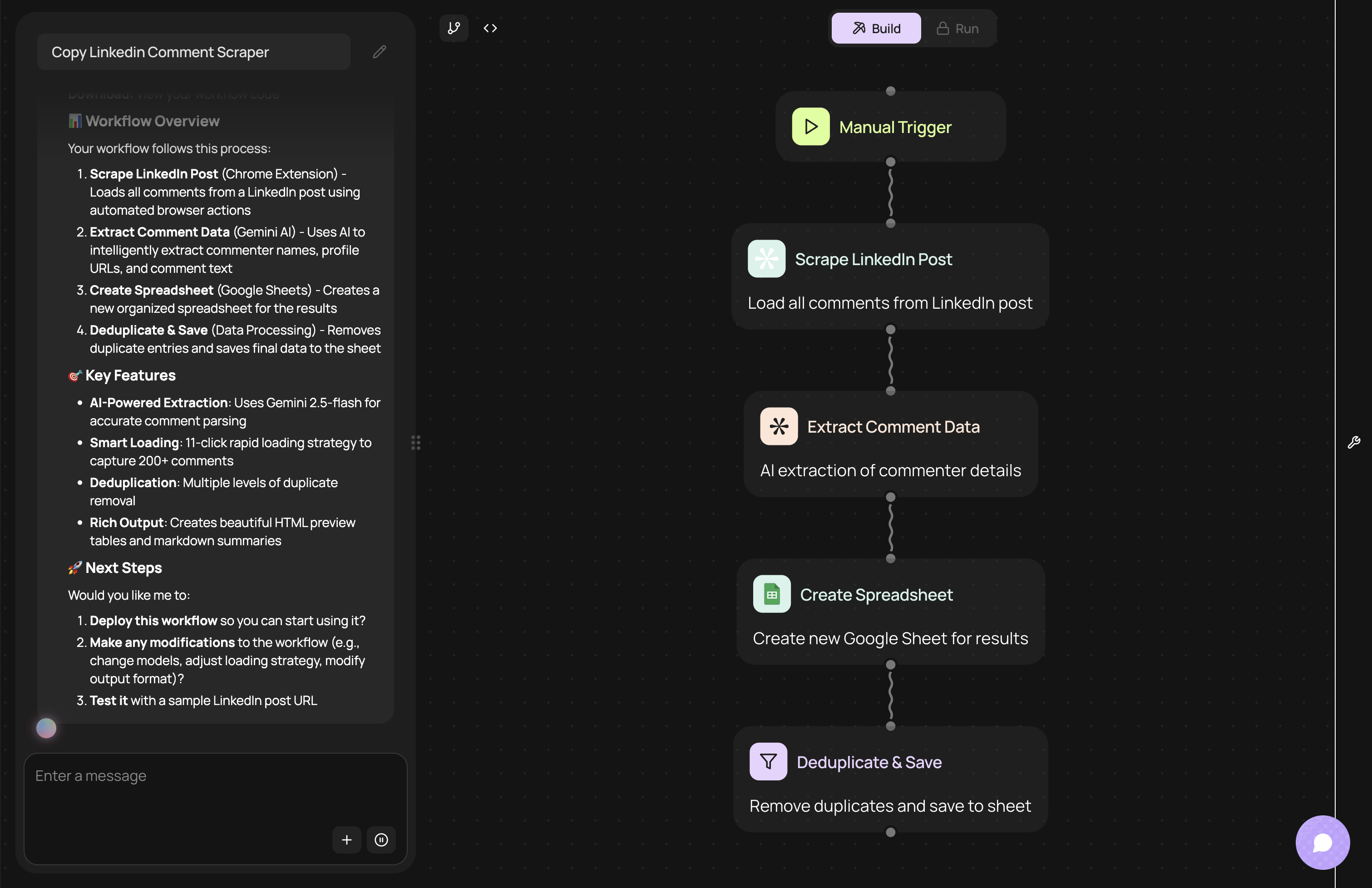
Architecting a modern LinkedIn scraper is about designing an adaptive, intelligent workflow, not writing brittle code. CodeWords provides the building blocks to construct these systems without getting bogged down in low-level details. The process becomes a logic-first solution. You focus on the what — the data points you need and the business rules — and let CodeWords figure out the how.
The first step is deciding the data you want to collect. This means defining the specific information you need and its relationships. A well-defined scope might include target profile attributes like job titles and industries, company page details like employee count, and job posting data such as required skills. This blueprint acts as a North Star for the AI.
You can also ask Cody, the CodeWords AI automation assistant for ideas that match your use case.
Next, simply describe your idea to Cody and it will build the workflow automation for you.
For example, let's create an automation that scrapes LinkedIn post comments and sends enriched profile data into your Google sheet. This is great for lead generation, competitor analysis, and building target audiences. Unlike with other no-code tools, CodeWords requires you only to describe your idea or ask to ideate. There's no need to architect your workflow automation through drag-and-drop, and you can configure integration connections in a couple of clicks.
This is where AI workflows change the craft. Old scrapers use fragile CSS selectors that break when a website's HTML structure changes. AI uses intelligent, context-aware selectors. Instead of telling it to "find the div with the class job-title," you tell it to "extract the job title." The AI understands the context and finds the information even if the underlying HTML changes. This resilience slashes maintenance time. In fact, AI-driven parsing has been shown to boost extraction speeds by 30–40% and hit up to 99.5% accuracy, even when a site’s layout changes.
CodeWords Workflow: Extract comments and profiles from LinkedIn posts
Prompt: Extract comments from a chosen post URL, send the results into a Google sheet, and simplify the data
Impact: Reduces weekly market research from 4 hours to 2 minutes.
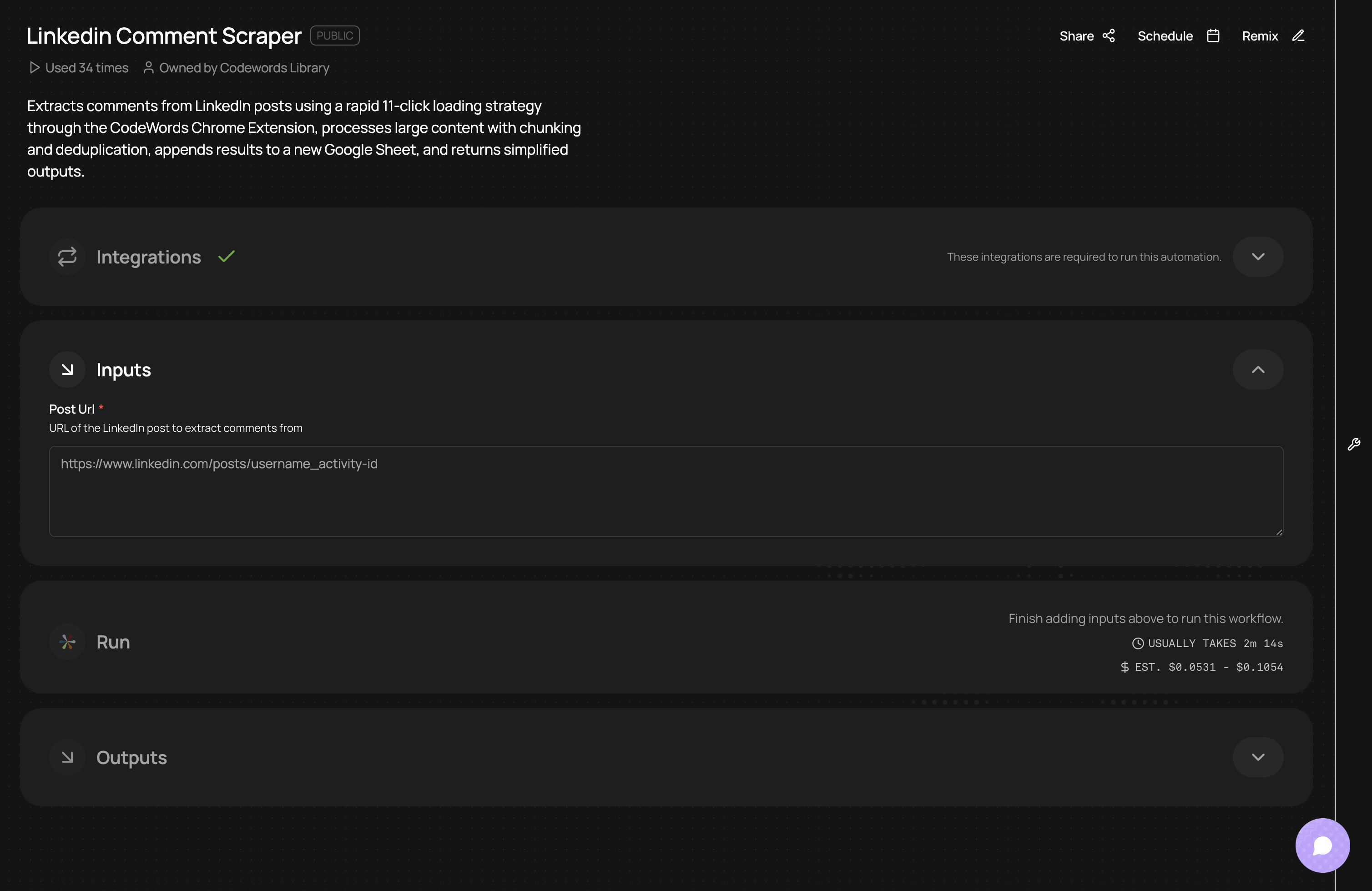
If you want to do more with this workflow, you can also click Remix to extend its functionality. For example, you can send the data directly into your CRM, a database like Airtable, or a communication tool like Slack. This end-to-end connection elevates a simple scraping task into a powerful business automation engine.
How do you scale and maintain your scraping operations?
Anyone can build a single LinkedIn scraper. The real craft is in making that scraper resilient and scalable. This is where engineering begins. It’s a shift from just pulling data to architecting a system that delivers it reliably, day after day. As you scale, you enter an arms race against sophisticated systems designed to block automated traffic.
Your scraper’s IP address is its fingerprint. To scale without being shut down, you need a robust proxy network, preferably using residential proxies that blend in with normal user traffic. Smart rotation of these proxies is crucial. Even then, you will encounter CAPTCHAs. A professional operation integrates with third-party CAPTCHA-solving services to handle these challenges programmatically.
The most persistent challenge is website updates. LinkedIn constantly tweaks its layout, breaking traditional scrapers that rely on rigid CSS selectors. This is where AI-powered parsing provides a significant advantage. By instructing the AI to "find the work experience" based on context rather than a specific HTML element, your system becomes vastly more resilient to cosmetic changes. This approach transforms maintenance from a constant fire-fight into managing a stable system. If you're new to this concept, learning the basics of how to extract data from websites is a great first step.
A production-grade scraping system must be built for failure. This means robust error handling, detailed logging, and a solid deduplication process to maintain data hygiene. By the end of 2025, the global web scraping market is expected to rocket past $9 billion — a clear indicator of the value companies place on reliable, automated data pipelines. The leap from a simple script to a self-healing, automated workflow is what separates hobbyists from true data architects.
Frequently asked questions
Is it really possible to scrape LinkedIn without my account getting banned?
Yes, but you have to act like a human, not a bot. This means using high-quality residential proxies, building in realistic delays between actions, and using modern automation tools that manage browser fingerprints to mimic natural navigation and lower your risk.
Can I scrape data from Sales Navigator or Recruiter?
Technically, yes, but it’s a high-risk game. These premium platforms are monitored closely. Scraping data from a paid account is easily traced and almost always results in a swift ban, costing you access to a tool you pay for. Focus on public profile data instead.
What's the best data format to store scraped profiles?
JSON (JavaScript Object Notation) is the professional standard. A LinkedIn profile has a nested structure — past jobs, skills, education — that is difficult to represent in a flat format like CSV. JSON handles this complexity perfectly and is universally supported by databases, CRMs like Salesforce, and other tools.
The implication of mastering this craft is clear. Instead of being a passive consumer of data, you become an architect of intelligence, building systems that give your organization a persistent information advantage. This is not just about efficiency; it's about creating a new operational capability.
Start automating now