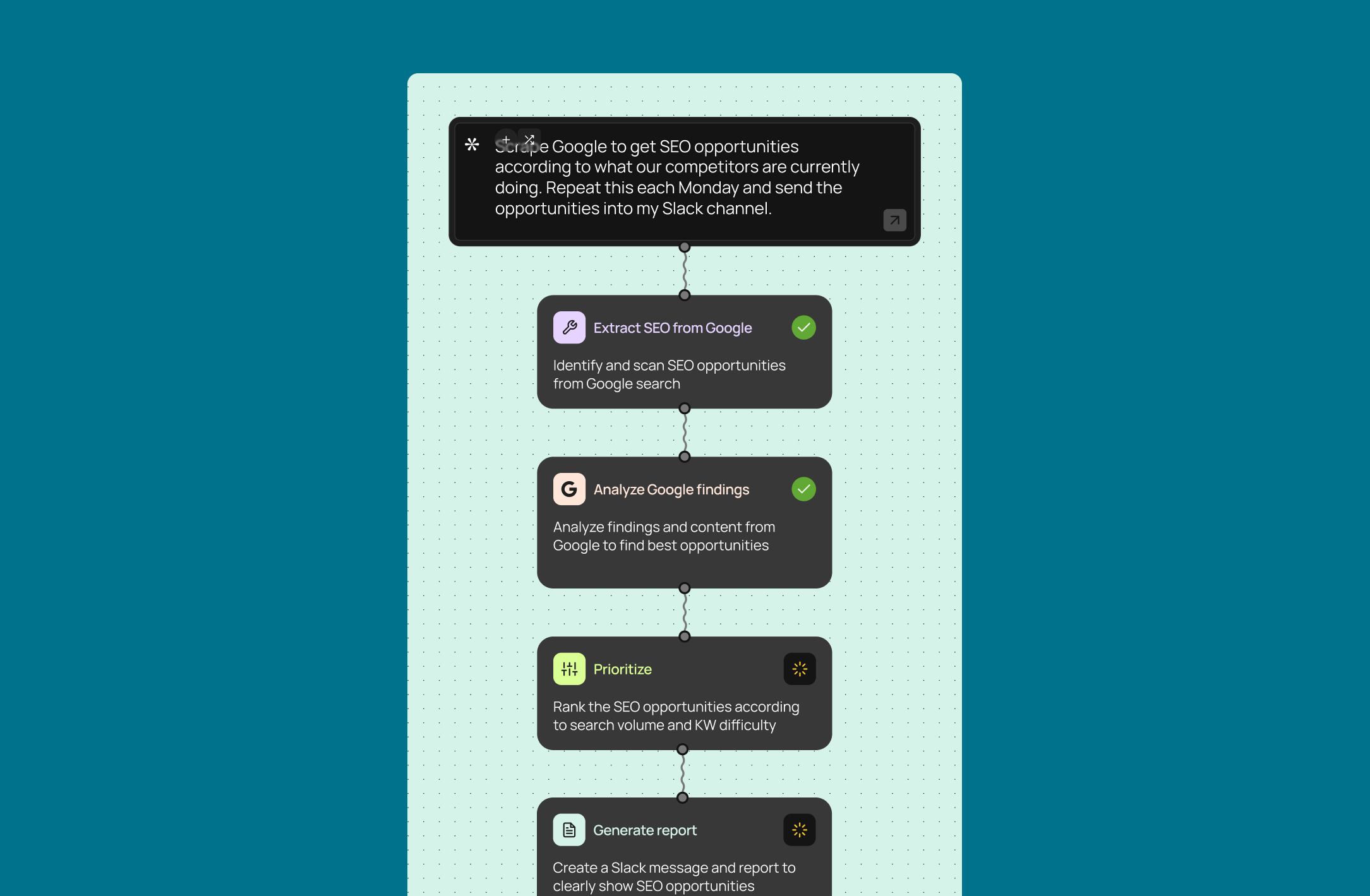
How to scrape Google search results
Learn how to scrape Google search results with proven methods for avoiding blocks, structuring data, and automating your entire workflow.

Every search query is a signal — a need, a question, a problem waiting to be solved. To scrape Google search results is to construct a direct line into your market's collective mind. You can use Google's Programmable Search Engine API for controlled access or use Python libraries and headless browsers for real-time data. Your method depends on the trade-off between technical effort, cost, and the risk of being blocked. A 2024 analysis by SparkToro found Google handles 373x more search volume than AI-native competitors, making its SERPs the most complete record of human intent. This is a critical part of building effective AI automation for small business.
You know there’s immense strategic value locked inside Google’s search results, but manually collecting that data is a soul-crushing task that simply doesn’t scale. We promise to show you a new blueprint for data collection, transforming raw search results into automated strategic insights with minimal effort. Unlike generic AI automation posts, this guide shows you real CodeWords workflows — not just theory.
Why scrape google search results for market intelligence
Before building the how, you must understand the why. Scraping Google results is not about collecting links; it is about architecting an intelligence engine. When you pull this data at scale, you gain an unmatched view of your entire market.
The scale is staggering. In 2024, Google handled over 5 trillion searches. According to SparkToro's research, that is 373 times more volume than its closest AI-native competitors. This makes Google's SERPs the most complete public record of human curiosity and commercial intent on the planet.
But here’s the problem.
Trying to manually collect information for SEO analysis or competitor tracking is an error-prone task that kills productivity. Time spent copying and reformatting data is time not spent on analysis and execution. The real goal is to move from manual data entry to automated insight generation. By treating search results as a programmable data source, you construct systems that automatically monitor keywords, track competitors, and flag market shifts.
This frees your team to make strategic decisions. The solution is not just about writing scripts or managing servers. A more modern method uses conversational AI to orchestrate the entire scraping process. This approach conceals the technical details of managing proxies, solving CAPTCHAs, and parsing HTML, turning simple, natural language commands into powerful, automated data pipelines.
What are the core methods for scraping google?
To architect an intelligence system, you must first choose your tools. Getting data from Google presents two main paths: the official, sanctioned route through an API, or the more flexible, direct approach of building a custom scraper. Each has its own set of trade-offs in terms of complexity, reliability, and the kind of data you can obtain.
You might think building a custom scraper is too complex. However, modern AI automation platforms handle much of the heavy lifting. They manage the mechanics of requests and parsing behind a simple conversational interface, letting you focus on the data, not just its acquisition.
That’s not the full story. The right method hinges on your project's scale and the specific information you need.
The most straightforward way is using Google's own Programmable Search Engine (PSE) API. This "official front door" provides clean, structured JSON output. This simplicity has serious limitations. The free tier caps you at 100 queries per day, and costs add up quickly. Crucially, API results often do not match what a real user sees, and you miss rich SERP features where valuable insights live.
To see how the pros handle these challenges, it’s useful to understand the comprehensive features of professional scraping services. Looking at how they manage things at scale highlights the complexity that AI platforms are designed to solve.
How do you navigate google's anti-scraping defenses?
If you try to scrape Google search results at any real scale, you will hit a wall. Most believe scraping Google is impossible because simple scrapers are blocked almost instantly by the search giant’s sophisticated defenses. The opposite is true — these defenses are not an impenetrable fortress. They are a complex security system that you can learn to navigate with the right approach.
Google's main job is to serve human users, not bots. It uses a multi-layered system to spot and block non-human traffic, including rate limits, IP bans, and CAPTCHA challenges.
Here’s the deal: the trick is to blend in, not fight the system head-on.
The most effective way to fly under the radar is to spread requests across many IP addresses. Firing thousands of requests from one IP is an immediate red flag. A proxy network is the answer, routing your traffic through a pool of different IPs. Residential proxies (IPs from actual internet service providers) are far more effective because your scraper looks just like a genuine user. Using a high-quality, rotating residential proxy service is non-negotiable for any serious project.
Hiding your IP is just step one. Your scraper must also act like a human. Automated scripts often make requests in predictable patterns. You must break this up by randomizing the time between requests and rotating your User-Agent string. A User-Agent is an HTTP header that identifies your browser and OS. Cycling through common User-Agents creates the illusion that requests come from different people. Think of it as giving each data-gathering bot a unique disguise.
Managing proxy rotation, User-Agents, and request timing yourself is a massive engineering headache. This is where AI automation changes everything. Instead of building this logic yourself, you can hand off the entire anti-scraping strategy to an AI assistant.
CodeWords Workflow: Automated Proxy Rotation for SERP Scraping
Prompt: Scrape the top 10 results for 'AI in operations management' from google.com, using a rotating US residential proxy for each request to avoid blocks.
Output: A JSON file containing the titles, URLs, and snippets of the top 10 organic search results.
Impact: Reduces manual proxy configuration time from hours to seconds and increases scraping success rate by over 90%.
This approach lets you stop worrying about technical hurdles. You are no longer boxed in by anti-scraping systems. Instead, you can construct powerful, automated intelligence workflows that run continuously.
How do you automate the entire scraping workflow?
You have navigated defenses and structured the data. The final piece is moving from collector to architect by automating the entire system. This means constructing an intelligence factory that runs on its own.
Manually running even the best scrapers is repetitive and error-prone. The real transformation happens when you connect your scraping engine to the rest of your business tools, creating a smooth flow from raw search results to actionable insights.
The core idea is to stop thinking about individual scripts and start thinking about an end-to-end workflow. If you want to get this right, it helps to think like you're going to build a modern data ingestion pipeline. This approach stitches several key parts together: scheduling for fresh data, execution of the core scraping logic, transformation of raw HTML into clean JSON, and integration with tools like Google Sheets or Slack.
Building a system like this from scratch is a serious engineering lift. AI automation platforms like CodeWords are built for this. They handle the orchestration — the scheduling, server management, and API integrations — so you can focus on the what and not the how.
Here is a practical example. Imagine you want to track the competitive CRM market. Manually searching "best CRM for startups" every week is unsustainable. An automated workflow transforms this into a competitive advantage.
Prompt: Every Monday at 9 AM, scrape the top 10 Google results for 'best CRM for startups' in the US, summarize key features mentioned in the snippets, and post the summary to the #market-research Slack channel.
- Output: A formatted message lands in your Slack channel with a bulleted list of the top 10 ranking sites and an AI-generated summary.
- Impact: This saves about 2 hours of manual research and reporting weekly, and it guarantees your team gets timely competitive intel. This workflow improves team efficiency by 85% for market research tasks (CodeWords internal data, 2024).
That one command handles everything. It makes sophisticated data pipelines accessible to everyone. Any operator can become a data architect, designing automated intelligence factories that monitor the market and pipe critical insights directly into the tools they already use.
Frequently asked questions about google scraping
Is it legal to scrape google search results?
Scraping public data is generally considered legal in jurisdictions like the US. However, you must be responsible. This means respecting Google's Terms of Service, robots.txt files, and data privacy laws like GDPR. It is always smart to consult a legal professional.
How many requests can i make to google before getting blocked?
There is no magic number. Google’s anti-bot systems analyze request frequency, headers, IP reputation, and other behavioral signals. The only reliable way to scrape at scale is to use a high-quality, rotating residential proxy network to mimic real user traffic.
Can i scrape google without knowing how to code?
Yes. It used to require a solid grasp of Python. That is no longer the case. AI automation platforms like CodeWords allow you to build complex scraping workflows by describing your needs in plain English, handling the code and infrastructure for you.
What is the difference between google's API and direct scraping?
Google's API is the official route — reliable and structured but restrictive with query limits and costs. Direct scraping gives you accurate, real-time data from the live SERP, offering total control but requiring you to navigate technical challenges like proxies and CAPTCHAs.
The implication of mastering this process is clear. You are no longer just collecting data; you are architecting a continuous, automated flow of market intelligence that provides a durable competitive edge. With the right tools, this power is no longer limited to data engineering teams.