The 12 best web data extraction tools for your 2025 tech stack
Find web data extraction tools that gather site data without coding.

The internet is a vast quarry of raw data, yet most of it is a liability. Unstructured information creates noise, not signal, burying teams in spreadsheets and outdated reports that obstruct clear decisions. The real challenge isn’t accessing data; it’s refining it into a strategic asset.
This guide provides a direct analysis of the best web data extraction tools that transmute raw web content into structured, actionable intelligence. We’ll show you how to move beyond simple scraping to build automated data pipelines. According to Gartner's 2023 forecast, by 2025, 70% of organizations will shift their focus from big data to small and wide data, prioritizing relevance over sheer volume. For non-technical teams, the manual process of gathering competitive pricing or market trends is a significant operational drag. You spend hours copying and pasting, only for the information to become obsolete almost immediately. This list promises to solve that problem by showcasing platforms designed for efficiency, from simple browser extensions to sophisticated AI-powered systems. We will explore each tool’s ideal use cases, pricing, and unique features. Unlike generic AI automation posts, this guide will show you real CodeWords workflows — not just theory.
You will find a direct path to selecting the right tool for your specific needs, whether you're a founder automating lead generation or a marketing team tracking brand mentions. Each review includes screenshots and direct links to help you get started quickly. We will move past surface-level descriptions to offer a clear, tactical assessment, enabling you to build a system that delivers refined, high-quality data directly into your workflows.
TL;DR: Best web data extraction tools
- By 2025, 70% of organizations will shift focus from big data to small and wide data, prioritizing relevance over volume (Gartner, 2023).
- AI-native tools like CodeWords build and maintain entire extraction workflows from a single natural language prompt, reducing setup from days to minutes.
- In New York, the average salary for a Data Engineer, a role often tasked with building these pipelines, exceeds $155,000 annually (Built In NYC, 2024).
What are web data extraction tools?
Web data extraction tools are applications designed to automatically gather and organize data from websites. These tools move beyond manual copy-pasting by using bots, or "scrapers," to navigate web pages, identify specific pieces of information — such as product prices, contact details, or customer reviews — and export it into a structured format like a spreadsheet or database. Most believe that web scraping is just for technical users. The opposite is now true. Modern platforms use visual interfaces and even natural language prompts, making sophisticated data collection accessible to non-coders.
This is important because automated extraction allows businesses to build proprietary data assets for competitive analysis, lead generation, and market research without dedicating extensive engineering resources. By transforming unstructured web content into a structured feed, these tools create the foundation for data-driven decisions.
How do you choose the right web data extraction tool?
Choosing the right tool depends entirely on your project's scale, the target website's complexity, and your team's technical skill.
For simple, one-off tasks on public websites, a browser extension or a visual no-code tool is often sufficient and offers the fastest path to results. However, there’s a problem most tools ignore: scalability and maintenance. As projects grow, or if websites implement anti-bot measures, these simpler tools often fail.
That’s not the full story. For mission-critical operations requiring high volume and reliability, an API-based solution with managed proxy rotation and JavaScript rendering is essential. This is where platforms built for developers shine. Ultimately, the best choice aligns technical power with operational need, ensuring the data pipeline is both effective and maintainable over time.
What are the best web data extraction tools available today?
1. CodeWords
CodeWords represents a significant evolution in workflow automation, positioning itself as a premier choice among modern web data extraction tools. Instead of relying on traditional, often cumbersome, drag-and-drop interfaces, the platform introduces a chat-native experience. Users simply describe their desired automation in natural language to Cody, the AI assistant, which then builds, tests, and deploys a complete workflow in seconds.
This approach fundamentally lowers the barrier to entry for non-technical users while retaining the power needed for complex tasks. Under the hood, CodeWords generates actual code, offering greater flexibility and expressiveness than the rigid, node-based systems of its predecessors. This unique combination makes it exceptionally well-suited for founders, operators, and business teams who need to move quickly without being constrained by technical limitations.
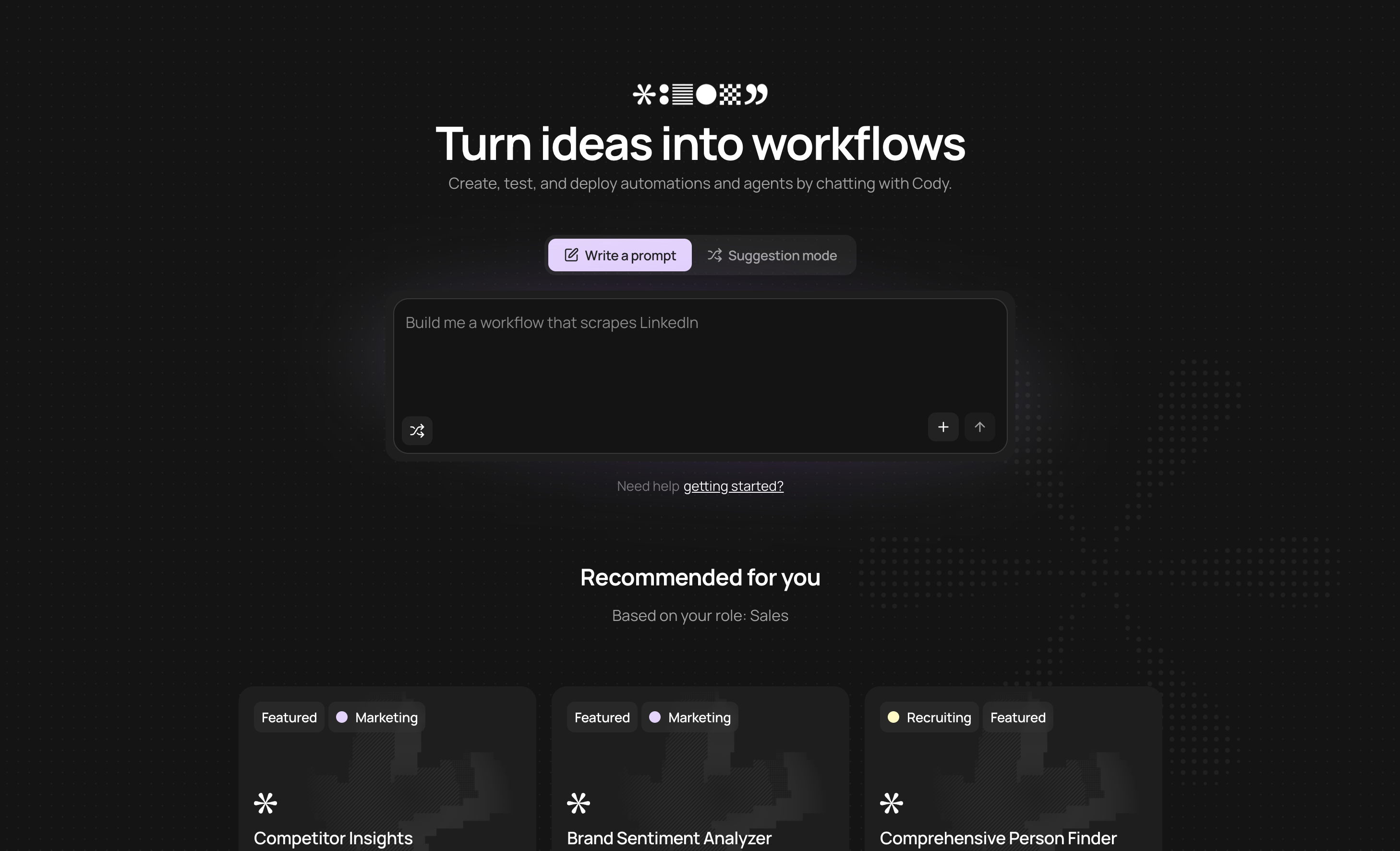
Why It Stands Out
CodeWords excels by merging a simple, conversational UI with a powerful, code-driven backend. Its library of over 2,700 integrations — including Google Sheets, Slack, Salesforce, and social media platforms — allows it to serve as a central hub for data movement and transformation across an entire organization's software stack.
Here’s the deal: The platform's growing gallery of community-built templates provides immediate starting points for common use cases like extracting Google Maps reviews or monitoring Reddit for brand mentions. This focus on community and transparency ensures users are well-supported.
CodeWords Workflow: Competitor Price MonitoringPrompt: "Every day at 9 AM, get the price and name for the top 5 products on this competitor's URL, then add the data to my 'Competitor Prices' Google Sheet."Output: A new row added to the specified Google Sheet with product name, price, URL, and timestamp.Impact: Reduces daily competitive analysis from 30 minutes of manual work to zero.
Key Features & Benefits
- Chat-First Workflow Creation: Describe your goal in one prompt and get a deployed automation instantly.
- Extensive Connectivity: Link over 2,700 apps to move and process data seamlessly.
- Automated Maintenance: Cody handles testing, debugging, and deployment, reducing manual oversight.
- Approachable Power: The code-based foundation allows for custom logic without requiring users to write code themselves.
Pricing and Access
CodeWords operates on a usage-based pricing model, making it accessible for both small-scale experiments and scalable for production workflows. New users receive $5 in free credits to test the platform.
Website: https://codewords.ai
2. Zyte (formerly Scrapinghub)
For teams that need enterprise-grade reliability and have some technical expertise, Zyte offers a powerful suite of web data extraction tools. Evolving from its roots as Scrapinghub, the platform is built around the popular open-source Scrapy framework, providing a robust ecosystem for developers. Its core offering, the Zyte API, is designed to handle the complexities of web scraping at scale, including managing proxies, solving CAPTCHAs, and executing JavaScript.
Zyte's pricing is a key differentiator. The API uses a success-based model, where you only pay for successful requests, with pricing tiers based on the complexity of the extraction (e.g., simple HTML vs. fully rendered pages). This contrasts with competitors who often charge for all attempts, regardless of outcome. For non-technical teams or those wanting a fully managed solution, Zyte Data provides complete data feeds with custom schemas, abstracting away the entire scraping process. You can learn more about how to extract data from websites using these types of powerful platforms.
Key Details & Use Cases
- Ideal User: Technical teams, data engineers, and enterprises needing scalable, reliable data extraction with a focus on compliance.
- Pricing: Success-based API pricing per 1,000 requests starting from free tiers to custom enterprise plans.
- Pros: Transparent and fair success-based pricing; deep integration with the Scrapy ecosystem; managed data delivery options available.
- Cons: Can be complex for non-developers; pay-per-result costs may increase for heavily protected websites.
- Website: https://www.zyte.com
3. Bright Data
For businesses requiring maximum success rates on heavily protected websites, Bright Data provides one of the most powerful and extensive platforms for web data extraction. Its core strength lies in its massive, ethically sourced proxy network, which gives its Web Scraper API an unparalleled ability to bypass blocks and retrieve data reliably. The platform caters to a wide spectrum of needs, offering everything from a do-it-yourself scraper IDE for developers to pre-built scrapers and fully managed data-as-a-service solutions for non-technical teams.
Bright Data's model is built for flexibility and scale, making it a go-to choice for enterprise-level operations. Users can choose from a pay-as-you-go model for the API, purchase pre-collected datasets, or commission fully custom scraping projects with guaranteed data delivery. While its extensive product catalog can seem complex to newcomers, its focus on compliance, robust tooling, and enterprise features like dedicated account management provides immense value. This makes it an ideal solution for organizations where data acquisition is a mission-critical function.
Key Details & Use Cases
- Ideal User: Enterprises, data-driven businesses, and teams needing high-success-rate scraping on complex or protected websites.
- Pricing: Pay-as-you-go options and monthly subscriptions for its API and proxy services; custom pricing for datasets and managed services.
- Pros: Extremely large and high-quality IP pool leading to high success rates; flexible options from a DIY API to fully managed builds.
- Cons: Pricing is geared toward enterprise use and can be expensive for small projects; the broad product suite can be overwhelming for beginners.
- Website: https://brightdata.com
4. Oxylabs
For businesses requiring industrial-strength infrastructure for their web data extraction tools, Oxylabs provides a comprehensive suite of solutions centered on reliability and scale. Its core offerings include a powerful Web Scraper API and an extensive network of proxies (residential, mobile, ISP, and datacenter), ensuring high success rates even on the most challenging websites. The platform is engineered to handle enterprise-level demands, managing everything from JavaScript rendering and CAPTCHA solving to maintaining user sessions, allowing technical teams to focus purely on data logic.
Oxylabs distinguishes itself with its enterprise-ready posture, offering 24/7 dedicated support and holding security certifications like ISO/IEC 27001, which is critical for organizations with stringent compliance requirements. Its flexible product suite allows users to choose the right tool for the job, whether it's a simple proxy for basic tasks or a sophisticated API for complex, large-scale scraping projects. While the platform is primarily API-driven and best suited for developers, its strong documentation and reliable performance make it a top-tier choice for businesses where data acquisition is a mission-critical function.
Key Details & Use Cases
- Ideal User: Data-intensive businesses, enterprises, and technical teams that need highly reliable and scalable proxy infrastructure and web scraping APIs.
- Pricing: Varies by product; Web Scraper API starts from $49/month. Proxies are priced based on traffic (GB) or IPs, with enterprise plans available.
- Pros: Exceptional reliability and performance at scale; extensive selection of proxy types for any use case; strong enterprise security and 24/7 support.
- Cons: Primarily developer-focused and requires API integration; costs can become significant for high-volume data extraction needs.
- Website: https://oxylabs.io
5. Apify
Apify bridges the gap between no-code simplicity and developer-grade power by offering a platform built around "Actors" — serverless cloud programs that can perform web scraping or automation tasks. This unique model allows non-technical users to quickly deploy powerful, pre-built scrapers from a public marketplace, while developers can build and run their own custom code. The platform is designed for scalability, handling everything from simple data lookups to complex, large-scale extraction projects that require sophisticated proxy management and cloud execution.
What sets Apify apart is its flexible, usage-based pricing model combined with a rich library of ready-to-use solutions. Instead of building a scraper for a popular social media site or e-commerce platform from scratch, you can find a maintained Actor in the Apify Store and run it immediately. Pricing is based on platform credits consumed by compute units and proxy usage, which provides a transparent way to pay for what you use. While the pricing model requires some initial learning to estimate costs for complex jobs, it offers a highly scalable and accessible entry point into the world of professional web data extraction tools.
Key Details & Use Cases
- Ideal User: Teams needing a quick path to production-grade scrapers, from non-technical users leveraging the marketplace to developers building custom solutions.
- Pricing: Usage-based model with a free tier; paid plans are based on platform credits for compute units and other resources.
- Pros: Extensive marketplace of ready-made scrapers; balances no-code accessibility with deep developer capabilities; clear, scalable pricing.
- Cons: Compute-unit pricing can be tricky to forecast for new users; building complex workflows may still require developer assistance.
- Website: https://apify.com
6. ScraperAPI
For developers and teams who prefer to build their own parsers but want to offload the headache of proxy management and anti-bot systems, ScraperAPI is an excellent choice. It acts as a specialized proxy layer, allowing you to make a simple API call to any URL, and it handles the complex backend work of IP rotation, CAPTCHA solving, and JavaScript rendering. This approach simplifies the scraping stack, letting developers focus solely on handling the returned HTML data rather than getting blocked.
The platform's appeal lies in its simplicity and predictable pricing model. Unlike services that charge based on bandwidth, ScraperAPI uses a credit-based system where one successful API call typically costs one credit, making it straightforward to estimate costs. For more complex targets requiring JavaScript rendering or residential proxies, the credit cost per request increases. While it doesn't offer the end-to-end data extraction features of a full platform, it is a powerful component for any custom scraping workflow. Understanding how such tools fit into a broader strategy is key, and you can explore more on how to construct a complete data pipeline with an API integration platform.
Key Details & Use Cases
- Ideal User: Developers and data teams building custom scrapers who need a reliable, managed solution for request handling and proxy rotation.
- Pricing: Credit-based plans with a free tier offering API credits for testing, and paid plans based on request volume and concurrency.
- Pros: Very simple to integrate into existing code; predictable request-based pricing; effectively handles proxies, retries, and browser rendering.
- Cons: Users are still responsible for parsing the HTML; credit costs can add up for sites requiring premium proxies or JavaScript rendering.
- Website: https://www.scraperapi.com
7. Octoparse
Octoparse positions itself as a user-friendly, no-code entry point into the world of web data extraction tools, making it ideal for non-technical users. It provides a visual, point-and-click interface that simplifies the process of building a scraper, moving beyond browser extensions to a full-fledged desktop application and cloud platform. Its workflow mimics human browsing behavior, allowing users to instruct the bot to click buttons, enter text, and loop through pages, all without writing a single line of code. The platform includes a library of pre-built templates for common targets like Amazon and Yelp, further lowering the barrier to entry for marketing and sales teams.
What distinguishes Octoparse is its tiered service model. Users can start with the self-serve desktop and cloud tools, but as their needs scale or complexity increases, they can opt for add-ons like residential proxies and automated CAPTCHA solving. For teams who want to completely outsource the work, Octoparse offers a full Data Service for end-to-end data delivery. This flexibility allows businesses to grow with the platform, starting with simple tasks and graduating to fully managed data streams. This approach makes it a practical example of no-code automation in action, providing accessible power to users without deep technical skills.
Key Details & Use Cases
- Ideal User: Marketers, sales teams, researchers, and business users needing an easy-to-use visual tool for data scraping without coding.
- Pricing: Free plan available with limitations. Paid plans start at $89/month (billed monthly) and scale up with more concurrent tasks and cloud access.
- Pros: Very intuitive point-and-click interface; pre-built templates for popular sites; scalable service options from self-serve to fully managed.
- Cons: The desktop app is Windows-first; complex sites with heavy anti-bot measures may require more expensive add-ons to scrape reliably.
- Website: https://www.octoparse.com
8. ParseHub
ParseHub stands out as one of the most user-friendly graphical web data extraction tools, offering a desktop application that allows non-developers to build scrapers by simply clicking on the data they want to extract. Its point-and-click interface is intuitive, simplifying complex tasks like navigating through pages, handling infinite scroll, and extracting data from interactive maps and dropdowns. This approach makes it highly accessible for marketers, researchers, and business analysts who need structured web data without writing a single line of code.
The platform operates on a freemium model that provides a clear upgrade path. The free tier is generous enough for small projects, allowing users to familiarize themselves with the tool before committing. For more demanding tasks, paid plans unlock features like scheduled cloud-based runs, IP rotation to avoid blocks, and integrations with storage services like Dropbox and Amazon S3. While its visual editor may require some patience to master for highly complex websites, its excellent documentation and tutorials provide a solid foundation for new users to grow their skills.
Key Details & Use Cases
- Ideal User: Non-technical users, marketers, and researchers needing an intuitive, visual tool for small to medium-sized projects.
- Pricing: Free plan available with limits. Paid plans start with the Standard tier and scale up to custom Enterprise solutions.
- Pros: Excellent point-and-click interface; great documentation for beginners; logical progression from a capable free tier to powerful paid features.
- Cons: The desktop application can be resource-intensive; complex dynamic websites may present a steep learning curve.
- Website: https://www.parsehub.com
9. WebHarvy
For users who prefer a one-time purchase over recurring subscriptions, WebHarvy offers a compelling proposition as a desktop-based, point-and-click data extractor. Sold as a perpetual license, this Windows-only application is designed for individuals and small teams tackling simple to moderately complex scraping jobs. It empowers non-technical users to visually select the data they need directly from a webpage, configure pagination rules, and extract content without writing a single line of code. Its strength lies in its simplicity and cost-effectiveness for long-term projects.
The primary differentiator for WebHarvy is its pricing model. Unlike the monthly fees common among cloud-based web data extraction tools, you buy it once and own it forever, with one year of free updates and support included. The tool handles common challenges like navigating categories, following links, and downloading images. However, this self-contained approach means users are responsible for managing their own proxies and implementing strategies to bypass advanced anti-bot measures. This makes it an excellent choice for straightforward data collection but less suitable for scraping highly protected, enterprise-level websites.
Key Details & Use Cases
- Ideal User: Individuals, small business owners, and researchers on Windows who need an affordable, offline tool for consistent, long-term scraping tasks.
- Pricing: One-time perpetual license starting around $139 for a single user, with multi-user and site licenses available.
- Pros: Cost-effective with no recurring fees; intuitive point-and-click interface that is easy to learn; handles pagination and data pattern detection.
- Cons: Windows-only application; requires users to manage their own proxies and anti-bot measures; lacks the scalability of cloud-based solutions.
- Website: https://www.webharvy.com
10. Diffbot
For organizations that need to move beyond simple page scraping and into structured entity extraction, Diffbot offers a suite of AI-powered web data extraction tools. Instead of writing site-specific rules, Diffbot uses computer vision and natural language processing to automatically identify and extract key entities like articles, products, people, and organizations from any URL. This approach transforms unstructured web pages into a clean, queryable database, drastically reducing the manual effort required to build and maintain individual scrapers.
Diffbot’s core value lies in its Knowledge Graph and extraction APIs, which not only pull data but also enrich it by connecting entities across the web. This is ideal for market intelligence, lead generation, or news monitoring where understanding relationships between data points is crucial. The platform operates on a credit-based pricing model, with different APIs consuming different credit amounts. While this requires some planning to map usage to costs, the free tier provides enough monthly credits for users to test its powerful capabilities.
Key Details & Use Cases
- Ideal User: Data scientists, developers, and enterprises needing enriched, structured entity data rather than raw HTML.
- Pricing: Credit-based system with a free tier providing 10,000 credits. Paid plans start at $299/month for higher credit allowances.
- Pros: Automatically extracts structured entities, minimizing the need for site-specific scrapers; provides powerful data enrichment and a web-scale Knowledge Graph.
- Cons: Not a direct replacement for traditional headless-browser scraping on all websites; the credit-based pricing model can be complex to forecast.
- Website: https://www.diffbot.com
11. Data Miner (Chrome/Edge extension)
For individuals and small teams needing quick, ad hoc data extraction directly from their browser, Data Miner is a highly accessible Chrome and Edge extension. It operates on a "recipe" system, where users can create or use pre-built templates to identify and pull structured data from a webpage with point-and-click simplicity. This makes it one of the faster web data extraction tools to learn for immediate tasks like scraping product listings, contact details, or social media profiles without writing any code.
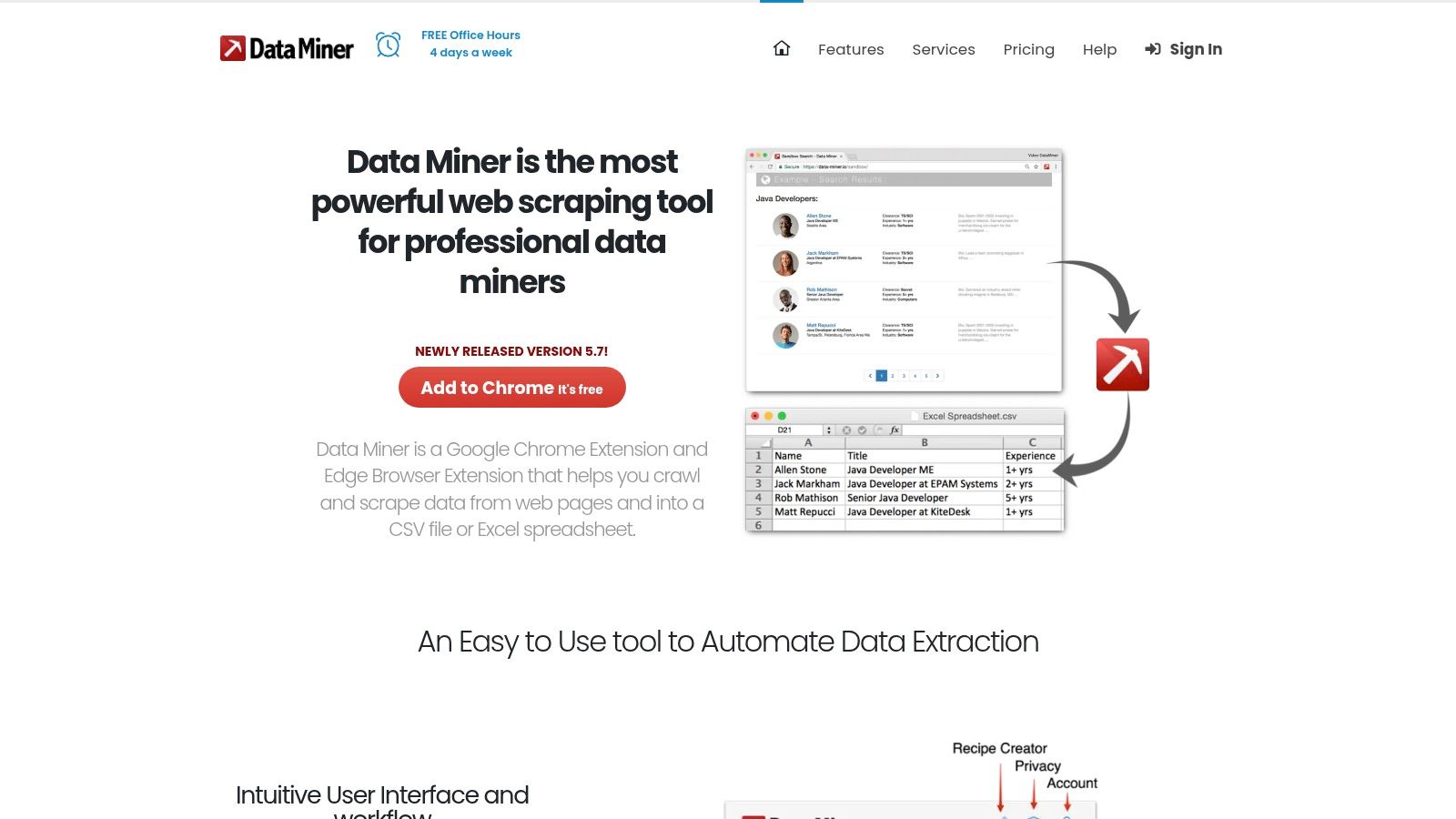
What sets Data Miner apart is its browser-native convenience and straightforward workflow. Users can automate pagination to scrape multiple pages and export findings directly into a CSV, Excel file, or Google Sheet. While its generous free tier is excellent for small jobs, the paid plans introduce higher page-per-month quotas and scheduling features for recurring tasks. It's an ideal solution for sales prospecting, market research, or any scenario where the data needed resides on simple, publicly accessible websites. However, its reliance on browser-based execution and strict page limits makes it less suitable for large-scale operations.
Key Details & Use Cases
- Ideal User: Marketers, sales professionals, and researchers needing a simple tool for quick, small-scale data collection tasks.
- Pricing: Free plan with 500 pages/month; paid plans with higher quotas and features start from $19.99/month.
- Pros: Extremely easy to learn and use directly within the browser; excellent for ad hoc extractions with direct spreadsheet exports.
- Cons: Monthly page limits can be restrictive for larger projects; some websites are restricted on the free tier.
- Website: https://dataminer.io
12. Web Scraper (webscraper.io)
Web Scraper offers one of the most accessible entry points into the world of web data extraction tools, beginning as a simple yet powerful browser extension. This approach allows non-technical users to build "sitemaps" or scraping recipes directly within their browser by pointing and clicking on the data elements they wish to extract. It’s an ideal starting point for those who need to gather data from multiple pages with consistent structures, like e-commerce product listings or business directories, without writing a single line of code.
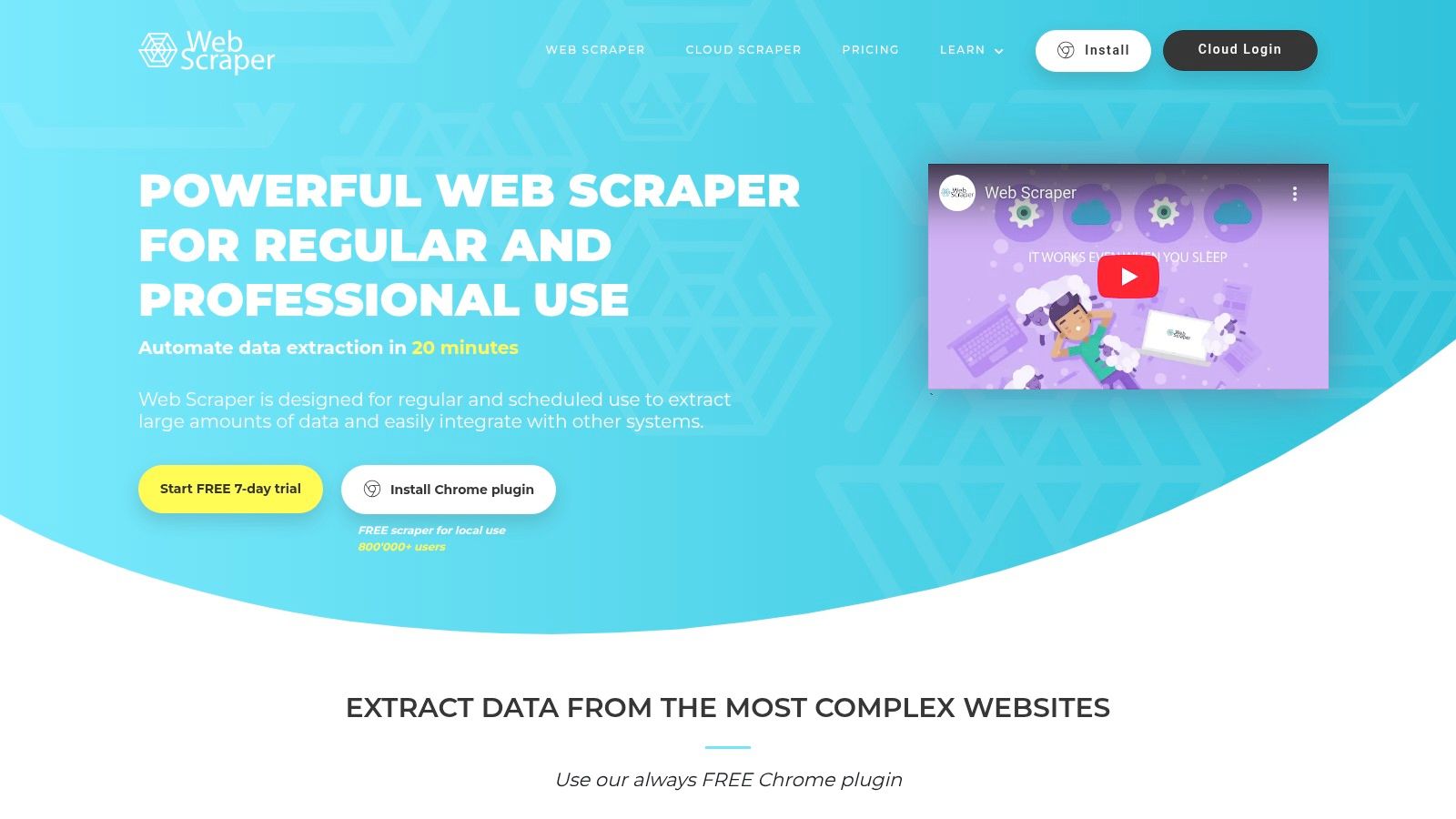
The platform's real strength is its seamless transition from a local tool to a scalable cloud solution. Once a scraper is built using the free extension, users can upgrade to Web Scraper Cloud to schedule automated runs, execute multiple tasks in parallel, and manage projects more effectively. The cloud service operates on a credit-based system for page loads and offers valuable features like IP rotation, API access, and integrations with Dropbox or Amazon S3. This two-tiered model provides a gentle learning curve, letting users master the basics for free before committing to a paid plan for more demanding projects.
Key Details & Use Cases
- Ideal User: Beginners, marketers, and small business owners who need a low-cost, visual tool for basic to intermediate scraping tasks with an option to scale.
- Pricing: Free browser extension. Cloud plans start with a free tier and scale up with monthly subscriptions based on URL credits, starting from $50/month.
- Pros: Extremely low barrier to entry with the free extension; visual point-and-click interface is very intuitive; offers a clear path to automation and scaling.
- Cons: Struggles with heavily dynamic or JavaScript-intensive websites; advanced anti-bot measures on some sites may require proxy add-ons at an additional cost.
- Website: https://webscraper.io
Frequently asked questions about web data extraction tools
Is it legal to use web data extraction tools?
Yes, it is generally legal to scrape publicly available data. However, you must comply with a website's terms of service, respect robots.txt files, and avoid scraping personal data, copyrighted content, or overwhelming a site's servers.
What's the difference between web scraping and web crawling?
Crawling is the process of indexing pages across the internet, like Google does. Scraping is the targeted extraction of specific data points from those pages. A crawler discovers URLs, while a scraper pulls structured information from them.
Can I scrape data from a website that requires a login?
Yes, many advanced tools can handle session management, allowing you to scrape data from behind a login wall. This typically involves configuring the tool to submit your credentials and maintain an active session cookie during the extraction process.
How to turn raw data into a strategic asset
The journey through the world of web data extraction tools reveals a fundamental shift. It’s no longer about simply collecting information; it’s about transmuting the raw, unstructured material of the web into refined, actionable intelligence. We’ve seen a spectrum of solutions, from the enterprise-grade power of Bright Data to the point-and-click simplicity of Octoparse. Each tool serves as a unique kind of refinery, designed for different types of crude data and for operators with varying levels of technical expertise.
The core implication is profound: you are no longer just a consumer of data, but a creator of proprietary data assets. The ability to systematically extract pricing information from competitors, monitor sentiment on social platforms, or compile lists of high-intent leads was once the exclusive domain of engineering teams. Now, these capabilities are accessible to anyone. The true power of modern web data extraction tools lies in their ability to democratize this process, turning operators, marketers, and founders into intelligence architects. Your unique insight into what data matters for your business can finally be translated directly into an automated system that feeds you a constant stream of strategic advantage.
You might think, "This still sounds too complex for my team to manage." The traditional view was that data extraction required deep technical knowledge to handle proxies, CAPTCHAs, and website structure changes. This is no longer the full story. The most significant development in this space is the rise of AI-native automation. Tools like CodeWords use natural language prompts to build and maintain the entire extraction workflow, effectively abstracting away the underlying complexity. A platform that can transmute a simple sentence into a production-ready data pipeline reduces the barrier to entry from weeks of learning to mere minutes of describing an objective. This is how you build a proprietary intelligence layer without hiring a dedicated data engineering team. The final step is not just collecting data; it's embedding it into the daily operations that drive your business forward.
Ready to turn web data into an automated competitive advantage? CodeWords allows you to build sophisticated web data extraction and AI workflows using simple, natural language prompts.
Start automating now